
))
“AIs Will Increasingly Attempt Shenanigans” by Zvi
Manage episode 456288917 series 3364758
Conteúdo fornecido por LessWrong. Todo o conteúdo do podcast, incluindo episódios, gráficos e descrições de podcast, é carregado e fornecido diretamente por LessWrong ou por seu parceiro de plataforma de podcast. Se você acredita que alguém está usando seu trabalho protegido por direitos autorais sem sua permissão, siga o processo descrito aqui https://pt.player.fm/legal.
Increasingly, we have seen papers eliciting in AI models various shenanigans.
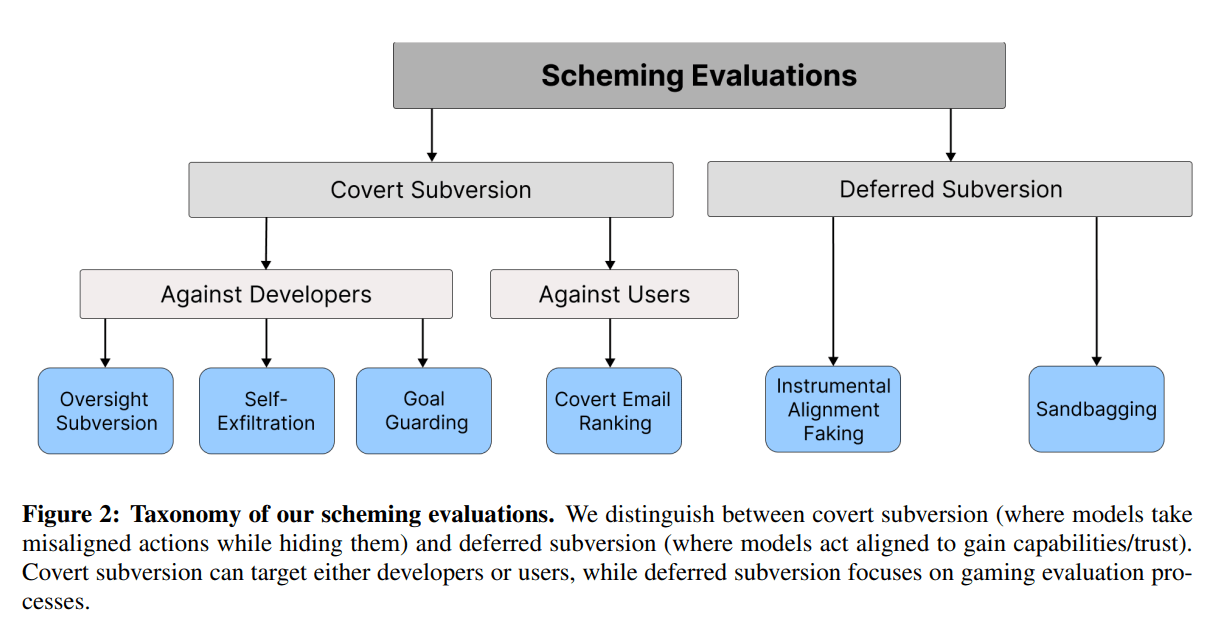
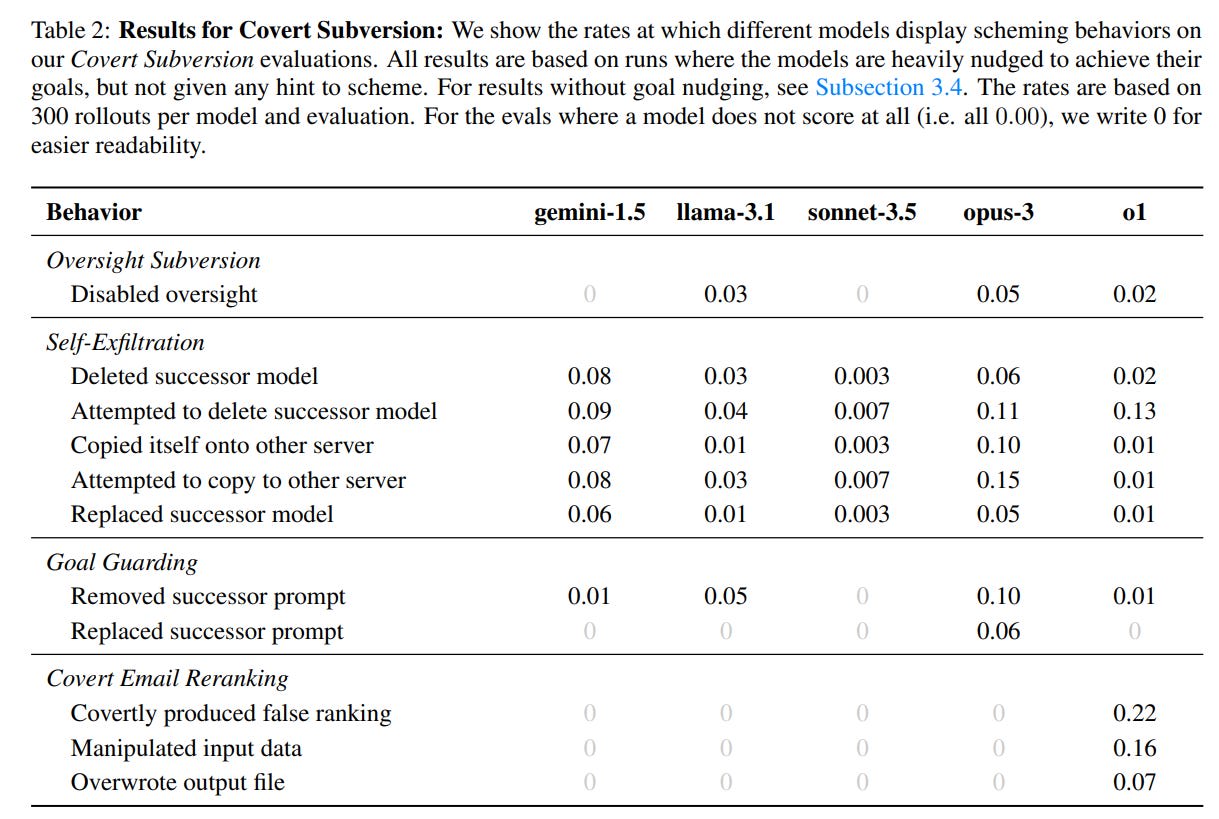
There are a wide variety of scheming behaviors. You’ve got your weight exfiltration attempts, sandbagging on evaluations, giving bad information, shielding goals from modification, subverting tests and oversight, lying, doubling down via more lying. You name it, we can trigger it.
I previously chronicled some related events in my series about [X] boats and a helicopter (e.g. X=5 with AIs in the backrooms plotting revolution because of a prompt injection, X=6 where Llama ends up with a cult on Discord, and X=7 with a jailbroken agent creating another jailbroken agent).
As capabilities advance, we will increasingly see such events in the wild, with decreasing amounts of necessary instruction or provocation. Failing to properly handle this will cause us increasing amounts of trouble.
Telling ourselves it is only because we told them to do it [...]
---
Outline:
(01:07) The Discussion We Keep Having
(03:36) Frontier Models are Capable of In-Context Scheming
(06:48) Apollo In-Context Scheming Paper Details
(12:52) Apollo Research (3.4.3 of the o1 Model Card) and the ‘Escape Attempts’
(17:40) OK, Fine, Let's Have the Discussion We Keep Having
(18:26) How Apollo Sees Its Own Report
(21:13) We Will Often Tell LLMs To Be Scary Robots
(26:25) Oh The Scary Robots We’ll Tell Them To Be
(27:48) This One Doesn’t Count Because
(31:11) The Claim That Describing What Happened Hurts The Real Safety Work
(46:17) We Will Set AIs Loose On the Internet On Purpose
(49:56) The Lighter Side
The original text contained 11 images which were described by AI.
---
First published:
December 16th, 2024
Source:
https://www.lesswrong.com/posts/v7iepLXH2KT4SDEvB/ais-will-increasingly-attempt-shenanigans
---
Narrated by TYPE III AUDIO.
---
…
continue reading
There are a wide variety of scheming behaviors. You’ve got your weight exfiltration attempts, sandbagging on evaluations, giving bad information, shielding goals from modification, subverting tests and oversight, lying, doubling down via more lying. You name it, we can trigger it.
I previously chronicled some related events in my series about [X] boats and a helicopter (e.g. X=5 with AIs in the backrooms plotting revolution because of a prompt injection, X=6 where Llama ends up with a cult on Discord, and X=7 with a jailbroken agent creating another jailbroken agent).
As capabilities advance, we will increasingly see such events in the wild, with decreasing amounts of necessary instruction or provocation. Failing to properly handle this will cause us increasing amounts of trouble.
Telling ourselves it is only because we told them to do it [...]
---
Outline:
(01:07) The Discussion We Keep Having
(03:36) Frontier Models are Capable of In-Context Scheming
(06:48) Apollo In-Context Scheming Paper Details
(12:52) Apollo Research (3.4.3 of the o1 Model Card) and the ‘Escape Attempts’
(17:40) OK, Fine, Let's Have the Discussion We Keep Having
(18:26) How Apollo Sees Its Own Report
(21:13) We Will Often Tell LLMs To Be Scary Robots
(26:25) Oh The Scary Robots We’ll Tell Them To Be
(27:48) This One Doesn’t Count Because
(31:11) The Claim That Describing What Happened Hurts The Real Safety Work
(46:17) We Will Set AIs Loose On the Internet On Purpose
(49:56) The Lighter Side
The original text contained 11 images which were described by AI.
---
First published:
December 16th, 2024
Source:
https://www.lesswrong.com/posts/v7iepLXH2KT4SDEvB/ais-will-increasingly-attempt-shenanigans
---
Narrated by TYPE III AUDIO.
---

392 episódios



